1.项目背景
随着中国经济的快速发展,上海作为国际化大都市,其房地产市场一直备受关注,购房者在面对庞大且复杂的楼盘信息时,往往感到困惑和不知所措,为了帮助购房者更好地了解市场行情,做出明智的购房决策,本项目选择了链家网上海市在售楼盘数据,进行了全面的数据分析和建模,希望能找出影响上海市房价的关键因素,并建立一个可靠的价格预测模型,为购房者提供科学的决策支持,将通过描述性分析、统计检验和机器学习模型的构建与优化,深入挖掘数据背后的价值,帮助购房者在纷繁复杂的房地产市场中找到最适合自己的房产。
2.Python库导入及数据读取
import pandas as pd
import numpy as np
import seaborn as sns
import matplotlib.pyplot as plt
from wordcloud import WordCloud
from collections import Counter
from scipy.stats import spearmanr
import statsmodels.api as sm
from statsmodels.formula.api import ols
from sklearn.preprocessing import LabelEncoder
from sklearn.model_selection import train_test_split
from sklearn.metrics import mean_squared_error, r2_score,mean_absolute_error
from sklearn.ensemble import RandomForestRegressor, GradientBoostingRegressor
data = pd.read_csv('D:/Desktop/商业数据分析案例/链家网上海市在售楼盘数据/链家上海市在售楼盘数据.csv')
3.数据预览与数据预处理
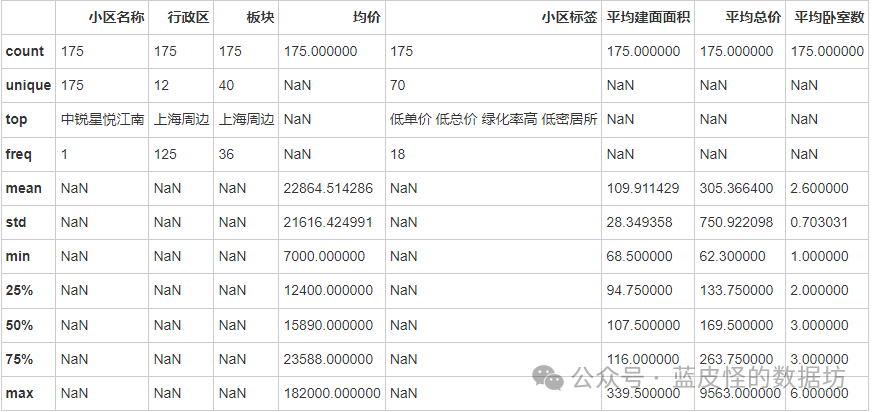
查看数据维度:
(180, 12)
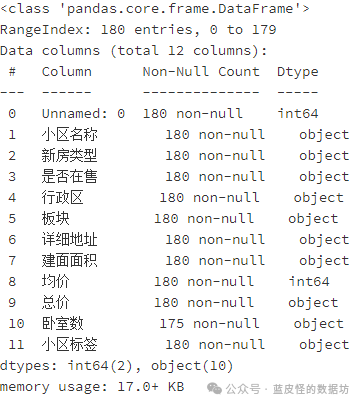
查看数据信息:
查看各列缺失值:
Unnamed: 0 0
小区名称 0
新房类型 0
是否在售 0
行政区 0
板块 0
详细地址 0
建面面积 0
均价 0
总价 0
卧室数 5
小区标签 0
dtype: int64
删除存在缺失值的行,占比较小,为了不影响后续建模预。
查看重复值:
0
查看分类特征的唯一值数量:

可以删除新房类型和是否在售这两个特征,因为是唯一的值,同样的针对详细地址也是直接删除,因为175个数据,就有175个值,表明这个特征对我们后续分析没作用。
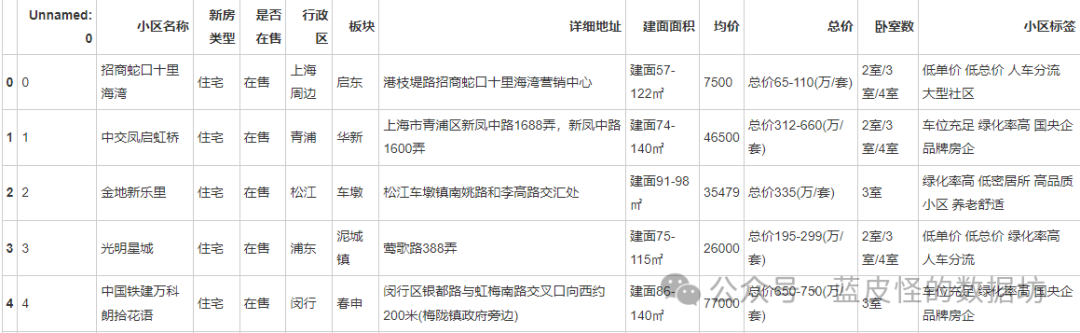
原始数据前5列
处理数据:取建面面积、卧室数、总价的平均值,并且删除无用特征。
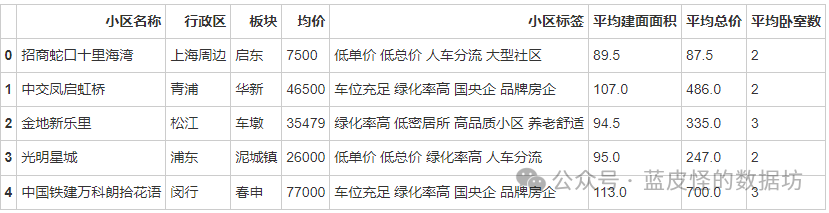
处理后的数据前5列4.描述性分析
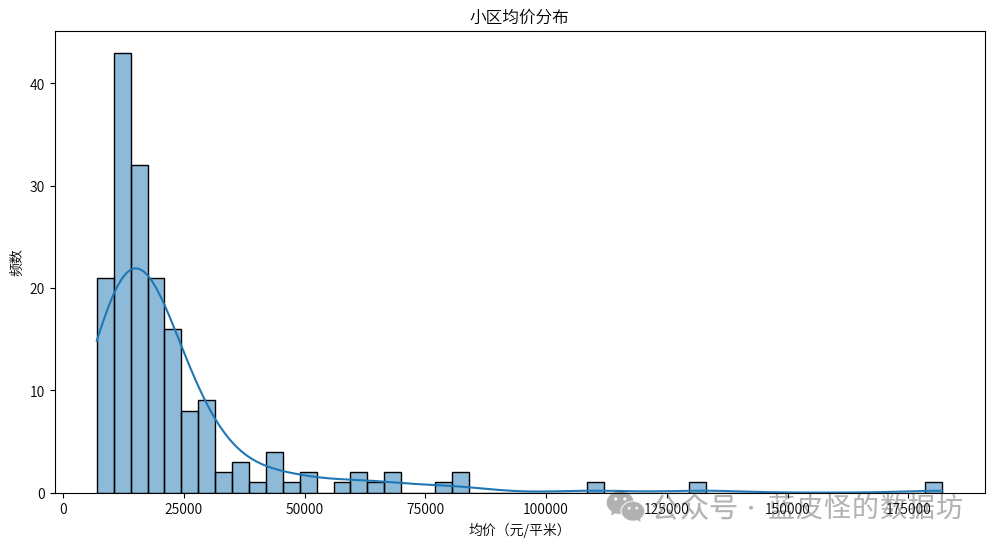
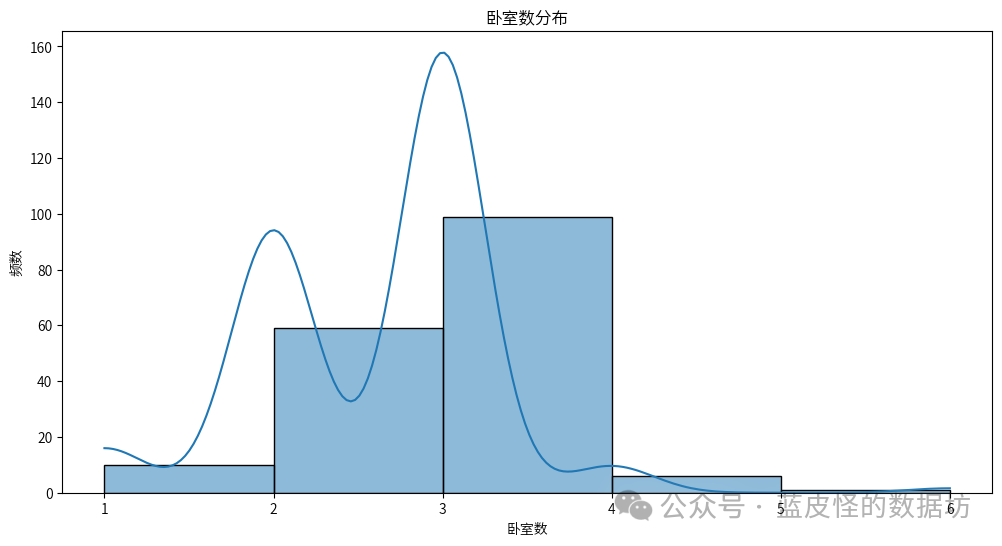
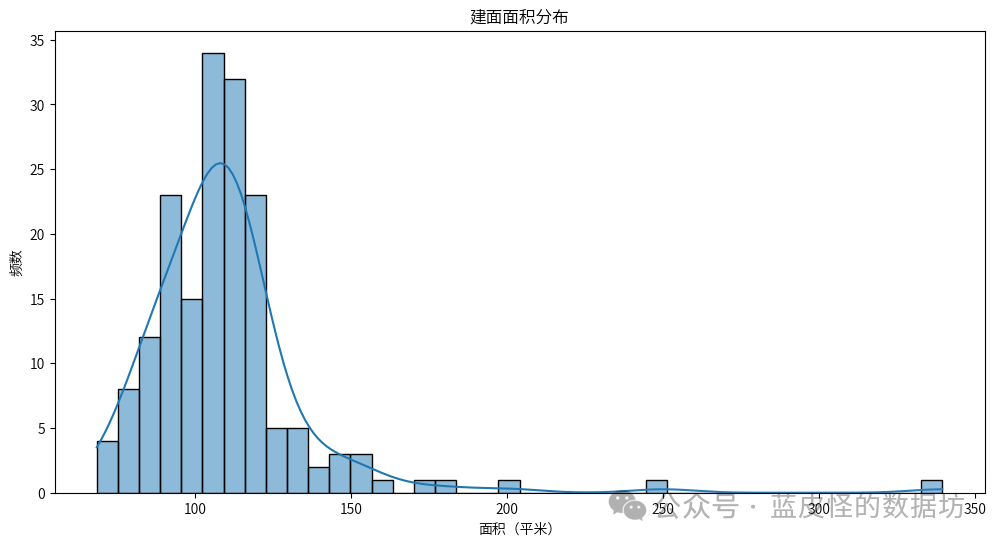
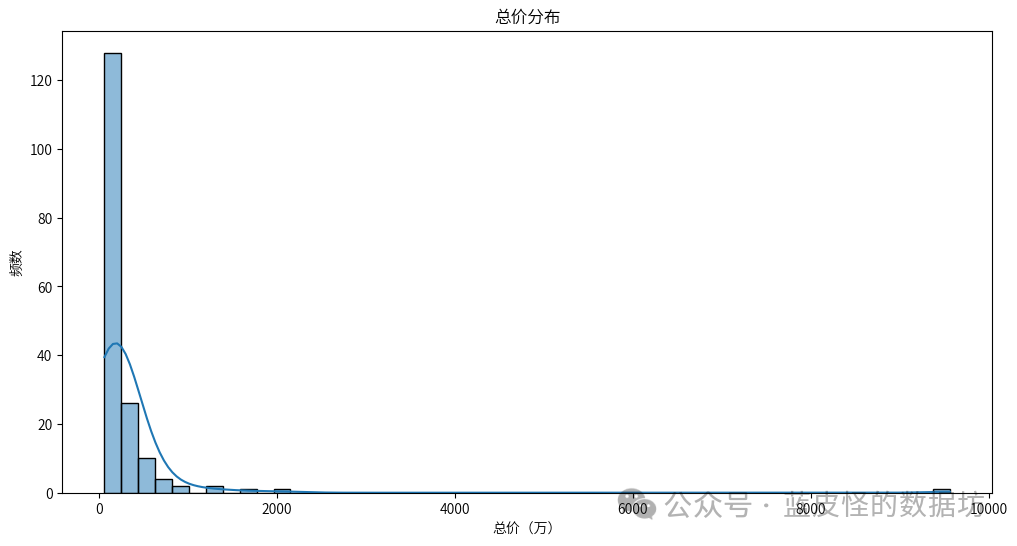

从词云图中可以看出,最常见的小区标签包括:
5.房价影响因素分析5.1斯皮尔曼相关性分析
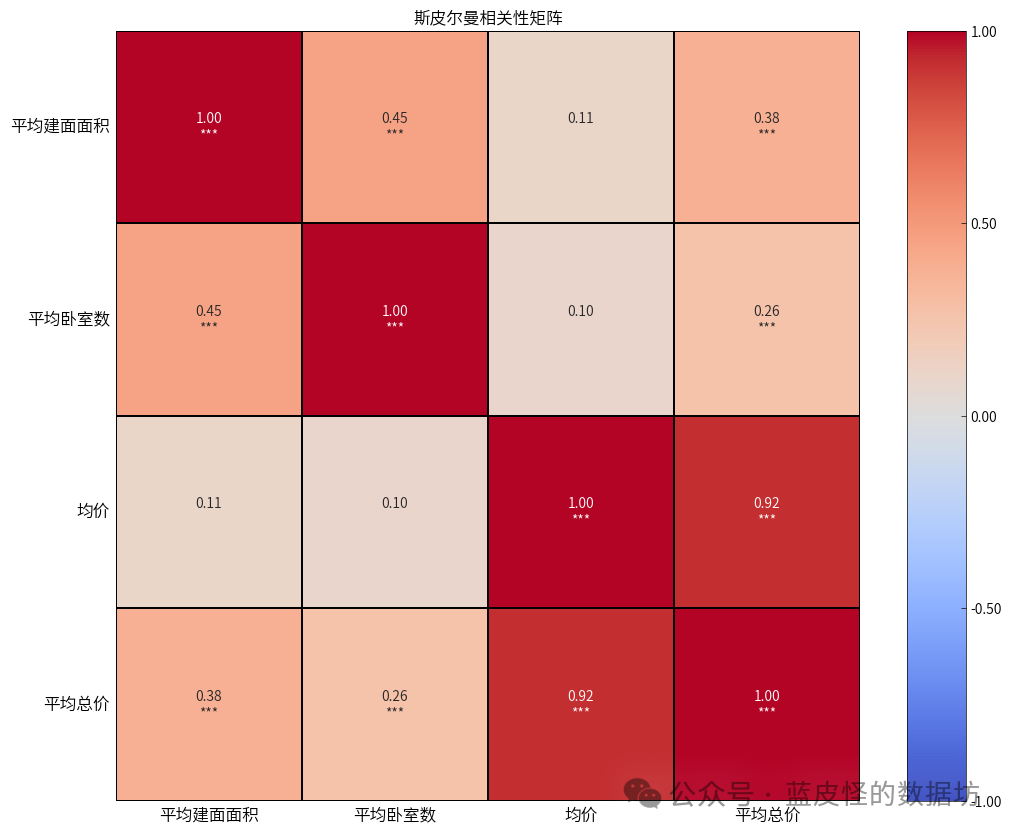
平均建面面积与平均卧室数、平均总价有中等相关性,说明更大的建面面积通常有更多的卧室,但是也需要出更多的钱,与均价不显著。
5.2方差分析
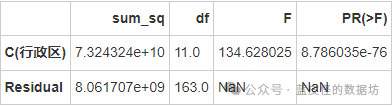
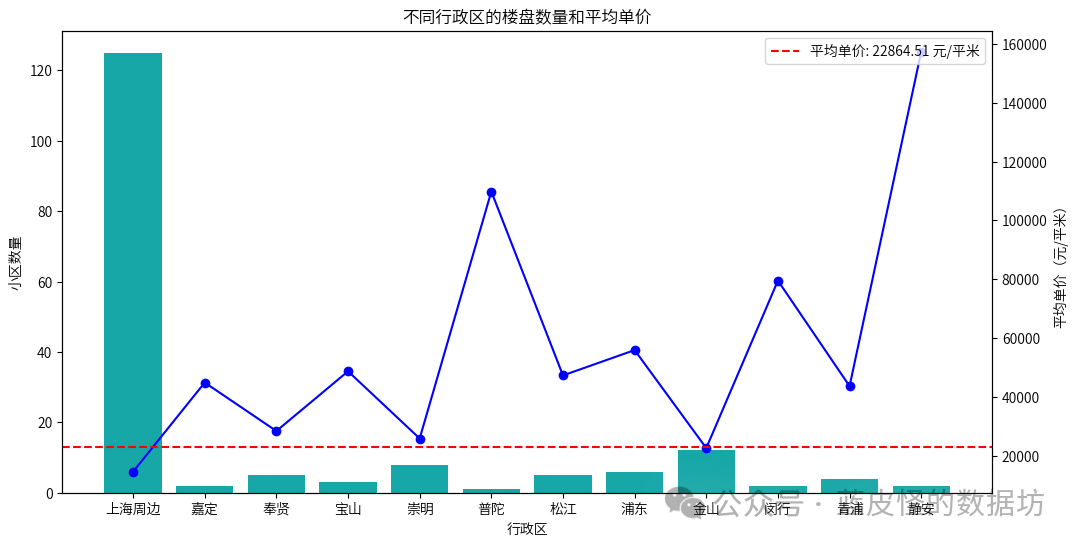
行政区对均价的影响
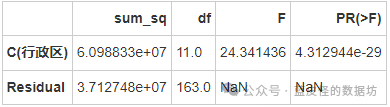
行政区对总价的影响
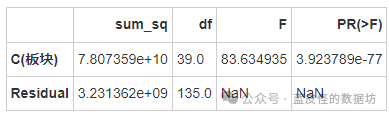
板块对均价的影响
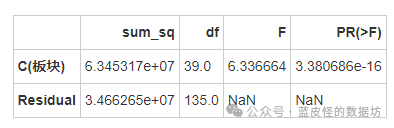
板块对总价的影响
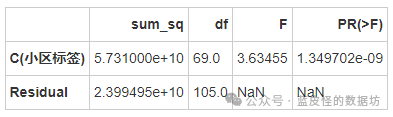
小区标签对均价的影响
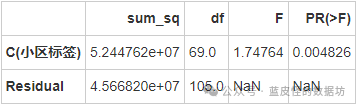
小区标签对总价的影响
无论是行政区、板块还是小区标签,对均价和总价的影响都具有统计显著性,这意味着不同的行政区、板块和小区标签对房价有显著影响。
6.随机森林6.1数据预处理
对每个小区,检查其标签并进行赋值,然后因为使用的是树模型,直接进行标签赋值。
6.2建立模型
模型预测总价的效果很差啊!进一步优化模型。
6.3优化模型
既然预测总价很差,不如试着去预测一下均价。
发现预测均价的效果明显优于预测总价的效果,用预测的均价和已知的建面面积,去预测总价,看看效果!
模型预测均价效果还行,但是预测总价效果一般,虽然通过预测的均价和已知的平均建面面积来预测总价,模型效果有提升,但是总体看下来,预测效果还是不理想。
7.梯度提升回归
考虑数据特征,这里不使用线性回归,而是使用树模型,因为树模型一般不会受到分类变量的影响,可以直接处理分类变量,并且能够很好地处理非线性关系和高维数据。
7.1建立模型
显著提升啊!但是还在不够,继续预测均价看看。
7.2优化模型
预测均价的效果也比随机森林回归模型好!

虽然有提升,但是不多,预测均价不错,但是用来预测总价,绝对谈不上理想……
8.总结
在本项目中上海房地产信息网链家,对上海在售楼盘数据进行了全面的数据分析和建模,旨在找出影响小区价格的显著因素,并建立一个可靠的预测模型。通过描述性分析、统计检验和机器学习模型的构建与优化,得到了许多有价值的结论:
数据特征:
斯皮尔曼相关性分析:平均建面面积与平均卧室数、平均总价有中等相关性,说明更大的建面面积通常有更多的卧室,但是也需要出更多的钱,与均价不显著。
方差分析:无论是行政区、板块还是小区标签,对均价和总价的影响都具有统计显著性,这意味着不同的行政区、板块和小区标签对房价有显著影响。
随机森林回归模型:直接去预测总价的话上海房地产信息网链家,效果不理想,误差较大,但是预测均价的话,效果较好,因此先预测均价,用预测的均价和已知的平均建面面积去预测总价,模型有提升。
梯度提升回归模型:无论是直接预测总价、均价,还是用预测的均价和已知的平均建面面积预测总价,梯度提升回归模型的效果均优于随机森林回归模型,然而,总的来说,预测总价的效果仍不够理想。结合数据来看,预测均价或许是更明智的选择,预测均价可以帮助购房者快速了解一个小区的价格,而总价最好针对具体房屋进行预测,并考虑户型、面积、朝向等因素。如果有这些详细数据,预测总价的效果会更好,然而在缺乏这些详细数据的情况下,从小区角度出发,预测小区的均价更能帮助购房者提前对小区有一个整体的认识。
各位读者可以在[和鲸社区]找到我发布的项目,有完整的代码和对应的数据集,并且在社区里面还能一键运行代码,麻烦各位读者动动发财小手,您的再看+分享就是对我最大的支持!谢谢!